Abstract
Machine-aided programming tools such as type predictors and code summarizers are increasingly learning-based. However, most code representation learning approaches rely on supervised learning with task-specific annotated datasets.
We propose Contrastive Code Representation Learning (ContraCode), a self-supervised algorithm for learning task-agnostic semantic representations of programs via contrastive learning. Our approach uses no human-provided labels, relying only on the raw text of programs.
In particular, we design an unsupervised pretext task by generating textually divergent copies of source functions via automated source-to-source compiler transforms that preserve semantics.
We train a neural model to identify variants of an anchor program within a large batch of negatives. To solve this task, the network must extract program features representing the functionality, not form, of the program.
This is the first application of instance discrimination to code representation learning to our knowledge. We pre-train models over 1.8m unannotated JavaScript methods mined from GitHub. ContraCode pre-training improves code summarization accuracy by 7.9% over supervised approaches and 4.8% over RoBERTa pre-training.
Moreover, our approach is agnostic to model architecture; for a type inference task, contrastive pre-training consistently improves the accuracy of existing baselines.
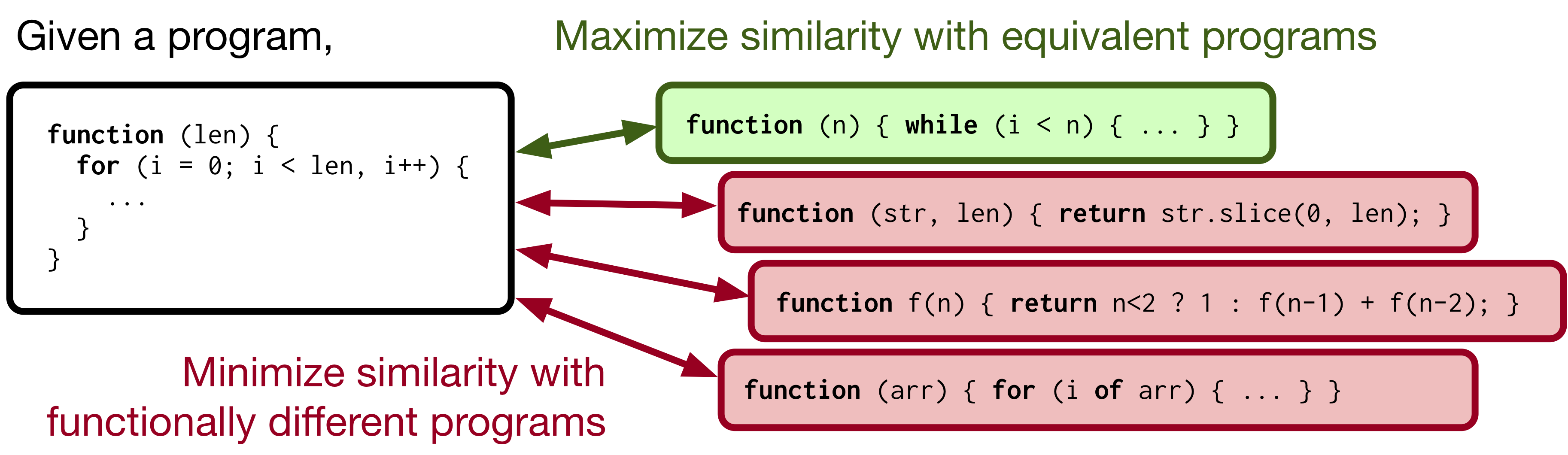 For many machine-aided programming tasks, programs with the same functionality should have the same underlying representation.
ContraCode learns such representations with contrastive learning: the network is trained to find equivalent programs among many distractors.
For many machine-aided programming tasks, programs with the same functionality should have the same underlying representation.
ContraCode learns such representations with contrastive learning: the network is trained to find equivalent programs among many distractors.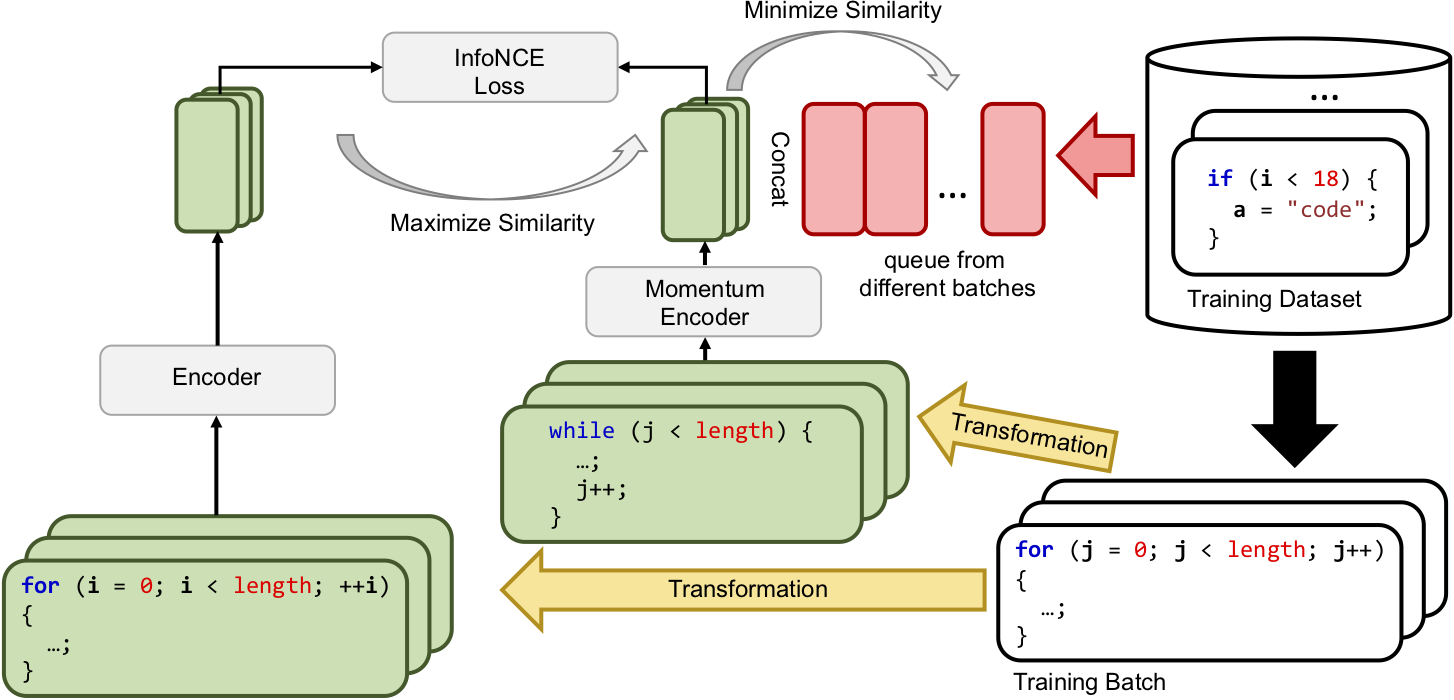 ContraCode extends the Momentum Contrast vision pretraining framework to learn an encoder of programs from a database of unlabeled programs and a suite of semantics-preserving transformations.
ContraCode extends the Momentum Contrast vision pretraining framework to learn an encoder of programs from a database of unlabeled programs and a suite of semantics-preserving transformations. After finetuning, an LSTM pretrained with ContraCode predicts the argument and return types of an untyped TypeScript method correctly, which can be useful for developers.
After finetuning, an LSTM pretrained with ContraCode predicts the argument and return types of an untyped TypeScript method correctly, which can be useful for developers.
 A finetuned model can also predict the name of a method from its body, a form of code summarization that demonstrates understanding of the code and could be useful for deobfuscation.
A finetuned model can also predict the name of a method from its body, a form of code summarization that demonstrates understanding of the code and could be useful for deobfuscation.